
The Spatial Configuration Task
This page last updated 2024/03/01
Description
The Spatial Configuration Task was created to be a quick and reliable measure of one's ability to generate and use a mental representation of a simple virtual environment. In the default implementation of the task, there are 5 simple geometric objects in a space-like virtual environment. At each trial, the user has to infer the unseen object that they are looking from - that is, the object the camera is 'sitting on' - based on the objects they can see. As the user never sees the entire environment at once, they begin by guessing. As the camera moves about the environment over successive trials, the user can begin to build a mental representation of where the objects are in relation to eachother, and use that representation to respond accurately. You can view a tutorial video explaining this task here: https://youtu.be/4gjRgqunI_M; this is the same video that participants are prompted to view in the in-task instructions.
In-task instructions
In this task, the 5 objects above are arranged pseudorandomly in the environment. At each trial, the camera will be placed on an object, and will be viewing at least 2 other objects. You are required to identify which object the camera is placed upon (i.e. looking from) at each trial.
The response options will be placed along the bottom of the screen, as seen below. Using your keyboard, indicate your response by pressing '1' for the image on the left, '2' for the middle image, and '3' for the image on the right. Holding the 'i' key will display these instructions again in case you forget.
After making a selection, the camera will move to a new object, viewing another set of objects, and the next trial will begin. There will be a total of 60 trials. The position and rotation of the objects in the environment does not change. When you start, you will be unfamiliar with the environment, simply guess if you are unsure of the correct response.
We have a short tutorial video for this task available online. If this is your first time performing the Spatial Configuration Task, we recommend you watch this video by pressing '1'. This will open the video in your default internet browser.
Stimuli
The environment is generated by selecting a random permutation of 5 objects from the 7 possible objects below: a cube, cylinder, icosphere, pentagonal prism, tetrahedron, top, and torus.







These objects are laid out in a roughly circular pattern in the virtual environment, and between trials the camera moves between objects. A sample layout and trial pair are depicted below.

A depiction of the camera movement between two sample trials.
After a participant responded at Trial 1, the camera would move from the pentagonal prism, the target response for trial 1, to the icosphere, the target response for trial 2. The camera begins rotating slightly before translating to prevent the user from guessing the target object from the initial translation vector (as the next target object is occasionally in view at the previous trial). During the task, the camera remains in-plane with the objects, and only two objects are simultaneously covisible. A top-down view is never shown to the user.
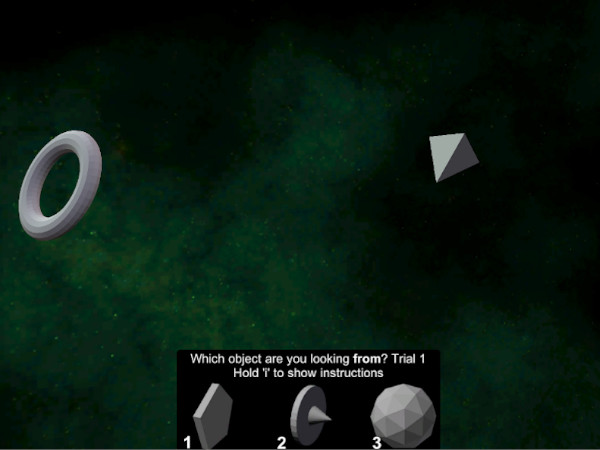
The user's view from the 'Trial 1' depicted above. Option 1, the pentagonal prism, is the target response.
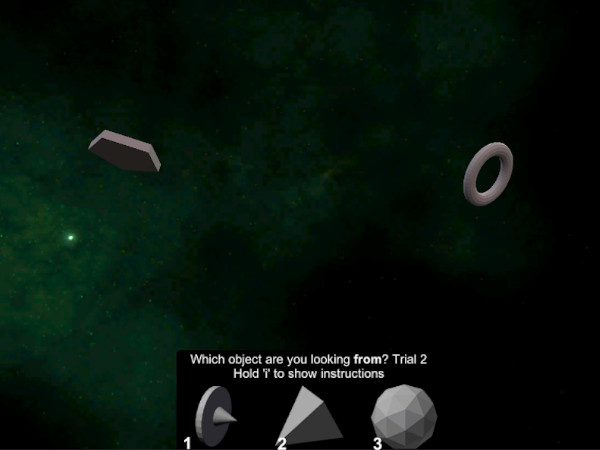
The user's view from the 'Trial 2' depicted above. Option 3, the icosphere, is the target response.
Trial structure
Default implementation has 60 trials, each with:
- Camera begins rotating (maximum 90 °/second) towards the target orientation for the present trial.
- 250 ms later, the camera begins translating (maximum 1 radius/second) to the target object.
- Once the camera is positioned and oriented, the response options appear. These remain until the user provides a response.
Empirical Data
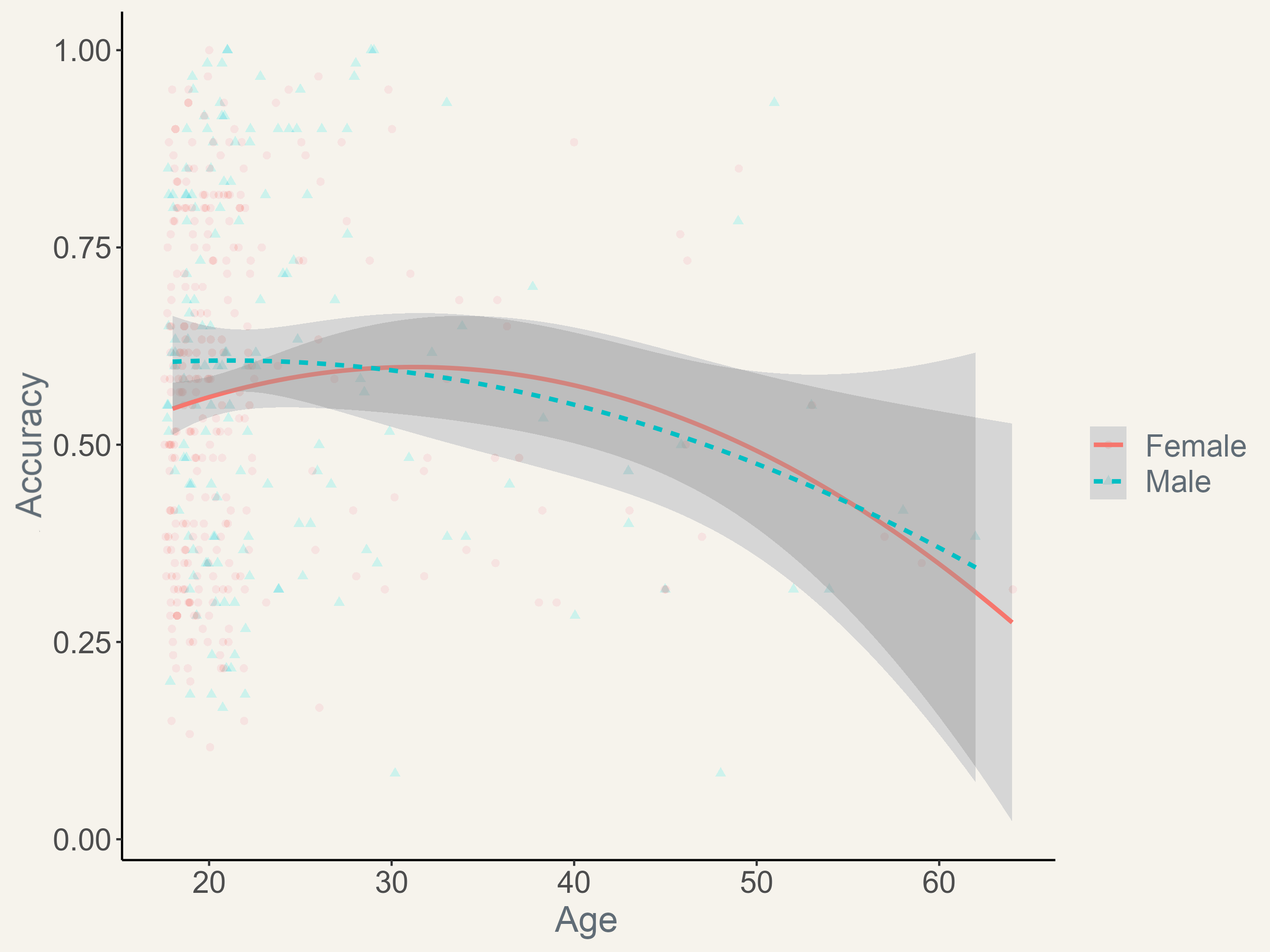
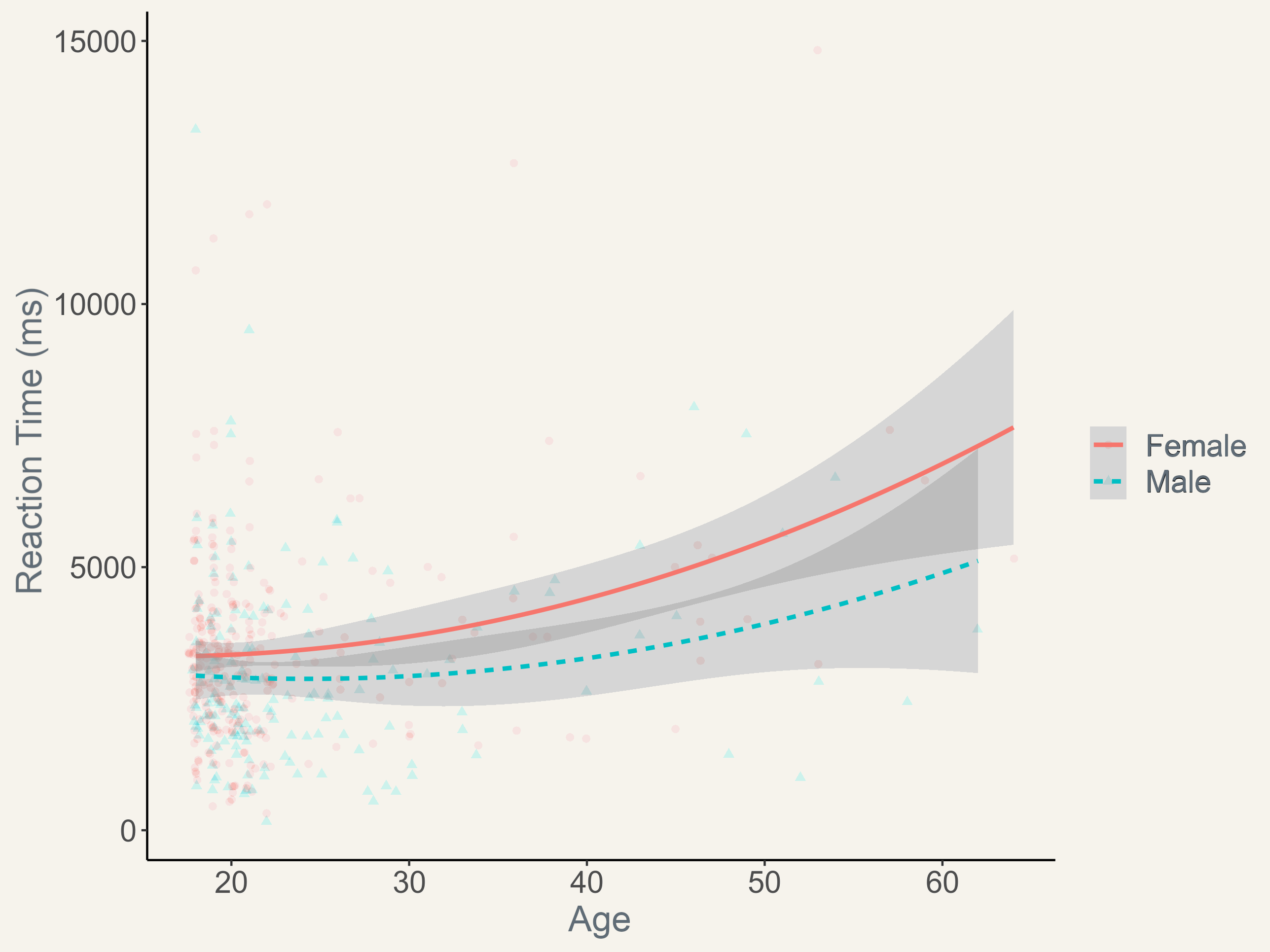
Peer-reviewed publications using this task:
2023 - The cognitive effects of playing video games with a navigational component 🔗
2022 - Investigating the relationship between spatial and social cognitive maps in humans 🔗
2020 - Behavioural and cognitive mechanisms of Developmental Topographical Disorientation 🔗
2020 - Aerobic Fitness Is Unrelated to the Acquisition of Spatial Relational Memory In College-Aged Adults 🔗
2020 - A pilot study evaluating the effects of concussion on the ability to form cognitive maps for spatial orientation in adolescent hockey players 🔗
2020 - A Novel Training Program to Improve Human Spatial Orientation: Preliminary Findings 🔗
2017 - Dorso-medial and ventro-lateral functional specialization of the human retrosplenial complex in spatial updating and orienting 🔗
Parametrization
The current version includes three researcher-defineable parameters: the instruction language, the number of trials in a run, and the number of objects in the environment (4-6). Note that altering the number of objects alters the number of response options. The response options provided are all unseen objects, i.e. the number of objects in the environment less two.
English, German, and Italian versions are available. The German translation - provided by Julia Poeschko - includes a translated version of the instructional video. The German version only supports the 'default' 5-object parameter. The Italian version supports any nTrials and nObjects, but does not inlude a translated instructional video.
Figure materials
You can download image assets to assist you in creating figures of the GettingLost.ca Spatial Configuration Task: spatial-configuration-sample-images.zip, 605 KiB. These files, and other information on this page, are licensed under a CC BY 4.0 license.
Change log
2023/10/30: Added Italian-language version thanks to Eduardo Naddei Grasso! German language instructions only work for the default 5 nObjects, but now works for any nTrials. Italian version works flexibly for any nObjects and nTrials.
2022/02/17: Added logging of the physical response selected to enable straightline detection. Added German-language version thanks to Julia Poeschko! German-language version only supports the default nObjects and nTrials of 5 and 60, respectively.
2020/08/19: Added AppType variable to distinguish WebGL from Standalone.
2020/08/10: Refactoring, WebGL version deployed, increased reporting verbosity: now includes objects visible, target object, and response option selected for each trial.
2019/05/22: V1.15. Minor performance improvements - mainly shaders and change in antialiasing.
2018/04/22: V1.14. CRITICAL BUG FIX from V1.12 which caused response options to be selected incorrectly. Data from V1.12 and V1.13 is bad.
2018/04/06: V1.13. Changed FOV calculation to more flexibly handle different screen sizes (including ultrawide) and object counts.
2018/03/31: V1.12. Added 6-object version.
2017/07/05: V1.11. Added option to view online tutorial video in instructions. Implemented FOV change to 55° if aspect ratio is 4:3
2017/06/25: V1.10. Added in numpad detection and response refractory period. Fixed a bug where if the participant loaded the 4-object version, subsequent 5-object versions would only load 4 objects.
2017/05/30: V1.09. Improved parametrization.
2017/04/24: V1.08. Main menu integration.
2017/02/06: V1.07. Integrated SCT with other online tasks, parameterized instructions to vary with the number of trials and the number of objects.
2017/02/02: V1.06. Created 4-object version. Fixed a bug where the viewed object at each trial were not selected completely randomly. Removed diamond object. Fixed adjacency view bug.
2016/08/27: V1.05. Improved server integration with available tasks
2016/03/02: V1.04. More server integration. Reaction times now saved in milliseconds, dropping sub-millisecond precision.
2016/02/02: V1.03. Changed camera movement calculations to improve performance when framerates are low or inconsistent. Camera rotation now begins slightly before translation, as it was possible to estimate the target object (which was often initially in view) based on the initial translation alone.
2015/10/20: V1.02. Gettinglost.ca integration. Improved instructions, camera translation smoothed.
2015/??/??: V1.01. Fixed bug where camera only viewed one object. Minor performance improvements.